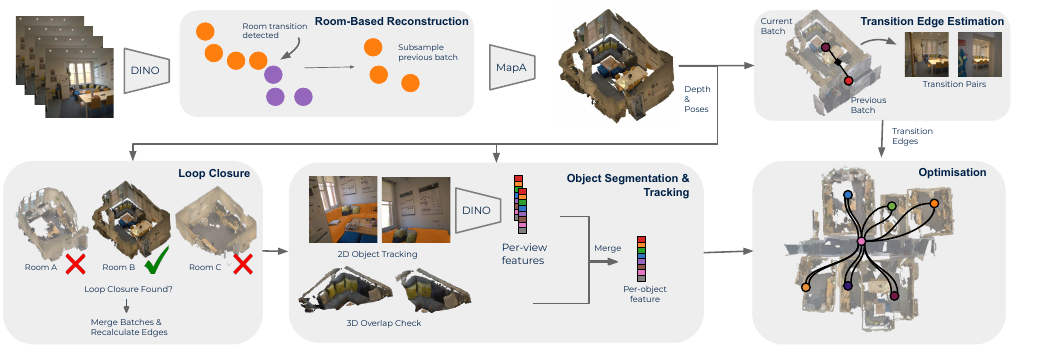
Scene graphs are becoming a standard representation for robot navigation, providing hierarchical geometric and semantic scene understanding. However, most scene graph mapping methods rely on depth cameras or LiDAR sensors. In this work, we present LEXI-SG, the first dense monocular visual mapping system for open-vocabulary 3D scene graphs using only RGB camera input. Our approach exploits the semantic priors of open-vocabulary foundation models to partition the scene into rooms, deferring feed-forward reconstruction to when each room is fully observed—enabling scalable dense mapping without sliding-window scale inconsistencies. We propose a room-based factor graph formulation to globally align room reconstructions while preserving local map consistency and naturally imposing the semantic scene graph hierarchy. Within each room, we further support open-vocabulary object segmentation and tracking. We validate LEXI-SG on indoor scenes from the Habitat-Matterport 3D and self-collected egocentric office sequences. We demonstrate improved trajectory estimation and dense reconstruction, as well as competitive performance in open-vocabulary segmentation. LEXI-SG shows that accurate, scalable, open-vocabulary 3D scene graphs can be achieved from monocular RGB alone.